

April 30, 2026
TLDR: got a bunch of agents to find remote unauth'd OOBs in ksmbd, CVE-2026-31432 and CVE-2026-31433. CVE-2026-31432 specifically is "RCE-promising" if you squint hard enough, given the memory layout. :) And then there's also 20+ other CVEs across Docker, OpenSSL, nginx, etc.
Finally, I go into some techniques that I tried/seem generally promising for making open-source LLMs better vulnerability researchers, like:
- getting them "drunk" to increase their creativity by steering their internal state, and
- performing a "brain surgery" to duplicate their reasoning layers, allowing them to connect more dots
Getting LLMs Drunk to Find Remote Linux Kernel OOB Writes (and More) · Hey, it's Asim
Using a self-orchestrating team of agents, with a dash of activation steering, to find vulnerabilities in everything from the Linux kernel to Docker and OpenSSL.
https://www.bloomberg.com/news/articles/2026-04-28/us-ends-investigation-into-claims-whatsapp-chats-aren-t-privateThe US has abruptly ended its investigation into claims that WhatsApp chats were visible to Meta. https://t.co/f1WXpQz58J
— Matthew Green (@matthew_d_green) April 28, 2026
I too woke up and choose violence today as the fail-copy POC dropped.
— rootsecdev (@rootsecdev) April 30, 2026
Made a clean exploit including fixing the UID post exploitation without rebooting the target server. Smoke those CTF’s in hack the box. https://t.co/nRiFyXQzRe
GitHub - rootsecdev/cve_2026_31431: Exploit POC for CVE_2026_31431 · GitHub
Exploit POC for CVE_2026_31431. Contribute to rootsecdev/cve_2026_31431 development by creating an account on GitHub.
rootsecdev/cve_2026_31431 (171 stars, Python) Exploit POC for CVE_2026_31431
source: rootsecdev (@rootsecdev)
“I wish we lived in the Tom Clancy world where analyst assessments form a decisive input into policy, but often decision makers already have strong assumptions about the situation...” -- Michael Kofman responds to my critique of Ukraine war predictions.https://t.co/9sir6VRpSN pic.twitter.com/j92hR9YSWb
— Seva (@SevaUT) April 29, 2026

Who Gets War Right? Michael Kofman Responds
a debate about military forecasting, broken clocks, and magic wands
So you’re telling me that Andean Medjedovic walked away with $65,000,000
— StarPlatinum (@StarPlatinum_) April 29, 2026
April 2026
- 23 years old
- Canadian math prodigy
- from Hamilton, Ontario
background
- finished high school at 14
- studied mathematics at University of Waterloo
described as “one of the brightest… pic.twitter.com/rXWfzUG822
Imagine a 19-year-old scrolling TikTok. She watches a creator list five "signs you have undiagnosed anxiety." She recognizes three in herself. By the end of the week, she's describing herself as anxious to her friends. A month later, she's avoiding situations she used to handle… pic.twitter.com/SOoYaU5CGc
— Michael Inzlicht (@minzlicht) April 29, 2026
https://michael-inzlicht.squarespace.com/s/The-psychological-consequences-of-mental-health-awareness-efforts.pdf
Twenty-three years ago the US said it was going to Americanize Iraq. Instead we got something closer to the Saddam-ification of the US. pic.twitter.com/gXsJrKYW9e
— Sam Haselby (@samhaselby) April 29, 2026
Not now honey - GitHub and Claude are both up at the same time
— Matt Johansen (@mattjay) April 29, 2026
Pretty cool, in-depth, root-cause analysis of the bugs used in the Adobe Reader zero-day attack (tracked as CVE-2026-34621 and other CVEs), delivered by the vulnerability research powerhouse @starlabs_sg ! https://t.co/GOsDsjHwzs
— Haifei Li (@HaifeiLi) April 29, 2026
CopyFail (CVE-2026-31431) in Go. In case you want to get root from a static binary without Python as a dependency.https://t.co/w5NYM3JBvJ pic.twitter.com/yxgLXGtr33
— Bad Sector Labs (@badsectorlabs) April 29, 2026
GitHub - badsectorlabs/copyfail-go: A Go implementation of copyfail (CVE-2026-31431) · GitHub
A Go implementation of copyfail (CVE-2026-31431). Contribute to badsectorlabs/copyfail-go development by creating an account on GitHub.
badsectorlabs/copyfail-go (107 stars, Assembly) A Go implementation of copyfail (CVE-2026-31431)
source: Bad Sector Labs (@badsectorlabs)
We didn't know how an actor was using EV Certificates issued to Lenovo and others.
— Squiblydoo (@SquiblydooBlog) April 29, 2026
We now do.
From DigiCert's incident report:
"the threat actor used a compromised analyst endpoint to access DigiCert's internal support portal. The threat actor used a limited function within… https://t.co/HbvxgIfCzr
2033170 - DigiCert: Misissued code signing certificates
ASSIGNED (dcbugzillaresponse) in CA Program - CA Certificate Compliance. Last updated 2026-04-28.
https://hackers-arise.com/satellite-hacking-listening-to-unencrypted-geo-satellite-traffic/ https://hackers-arise.com/satellite-hacking-building-the-ground-station-for-satellite-tracking-and-radio-communication/ https://hackers-arise.com/satellite-hacking-how-russia-knocked-out-the-viasat-system-at-the-outset-of-the-ukraine-war/Satellites can be hacked. Here’s how it happens:
— Aircorridor (@_aircorridor) April 28, 2026
1. Listening Satellite Traffic -> https://t.co/ZxuhHCBdBI
2. Tracking Satellites -> https://t.co/LVr74MBhyi
3. How Russia Knocked out the ViaSat System at the Outset of the Ukraine War -> https://t.co/zx9V0136qJ@three_cube pic.twitter.com/Jx9sQmA4Q8
Honestly, it's kind of beautiful https://t.co/almhqdVUOm pic.twitter.com/8v1rqQKV0S
— Brendan Dolan-Gavitt (@moyix) April 29, 2026
Out of 30 fixed security issues, 21 were found internally by Google. VR is cooked fr. https://t.co/L3BDKkEWqG pic.twitter.com/RaCvB3bRbp
— Devansh (⚡, 🥷) (@0xAsm0d3us) April 29, 2026

Chrome Releases: Stable Channel Update for Desktop
The Stable channel has been updated to 147.0.7727.137/138 for Windows/Mac and 147.0.7727.137 for Linux, which will roll out over the comin...
https://openai.com/index/cybersecurity-in-the-intelligence-age/We've released a new 5-point action plan for strengthening cyber defense.
— OpenAI Newsroom (@OpenAINewsroom) April 29, 2026
AI is reshaping cybersecurity. The same capabilities that help defenders may be used by malicious actors.
One approach is to treat these systems as too dangerous for broad defensive use and limit them to…
Journalists reporting on China should be aware of ways the authorities may respond to their work. Here's what happened to @ICIJorg and its network following a 2025 exposé on Beijing’s tactics to threaten, coerce and intimidate regime critics overseas. https://t.co/kGXs8PegQC
— Runa Sandvik (@runasand) April 28, 2026

Phony whistleblowers, fake journalists and cyber spies: ICIJ network targeted after China Targets probe - ICIJ
Shortly after publication, a slew of fake ICIJ reporters approached journalists, Taiwanese officials, and human rights advocates seeking sensitive data. With Citizen Lab, we investigated.
CVE-2026-31431 a/k/a CopyFail
— vx-underground (@vxunderground) April 29, 2026
> Linux LPE
> Description sounds like AI slop
> Exploit is legit
> Impacts every Linux kernel from 2017 - Now
> Proof-of-concept released
> It's Wednesday?https://t.co/FXgjWW7lOV

Copy Fail — CVE-2026-31431
CVE-2026-31431. 100% Reliable Linux LPE — no race, no per-distro offsets, page-cache write that bypasses on-disk file-integrity tools and crosses containers. Found by Xint Code.
The operator installed Komari as a persistent Windows service, “Windows Update Service,” via NSSM, pulling it directly from the official Komari GitHub repository.
— Huntress (@HuntressLabs) April 29, 2026
No attacker-controlled infrastructure was needed to stage the loader.
Get the details. 👇https://t.co/iNB8NlL2sc
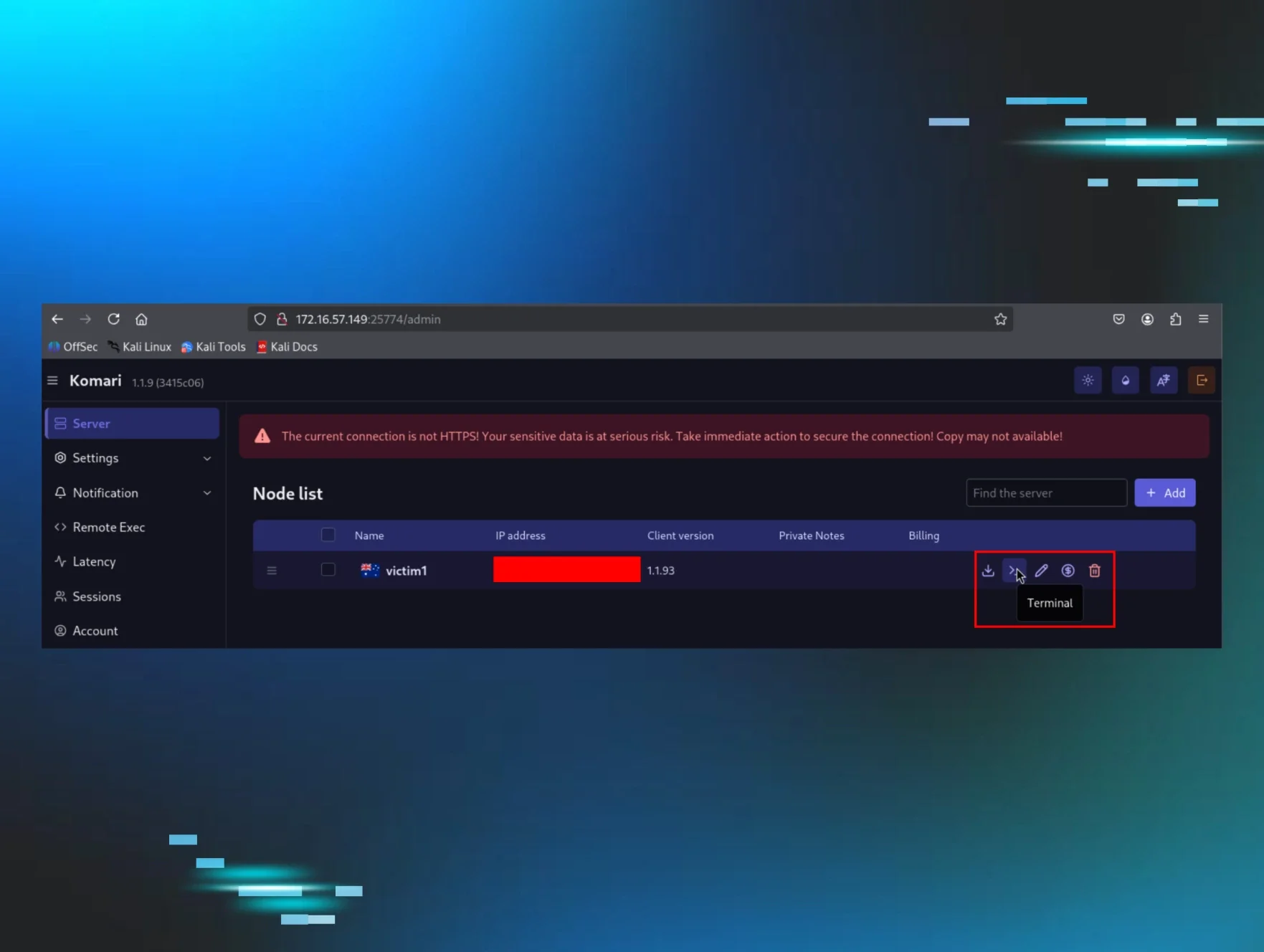
Komari Red: The Monitoring Tool with a Built-in Reverse Shell | Huntress
Huntress found threat actors using the Komari monitoring agent as a SYSTEM-level backdoor. Learn how they abused GitHub and what defenders should hunt for.
On April 16, 2026, a threat actor used stolen VPN creds to pivot into a Huntress partner Windows workstation and dropped a SYSTEM-level backdoor using the Komari agent - a 4.3k-star, MIT-licensed, Go-based project on GitHub. 👇🧵
— Huntress (@HuntressLabs) April 29, 2026
Paper plate armor. https://t.co/cZm3v3dP54
— thaddeus e. grugq (@thegrugq) April 30, 2026
https://www.bloomberg.com/news/articles/2026-04-29/chinese-hackers-spied-on-cuban-embassy-as-us-prepared-blockade?embedded-checkout=true🇨🇳 hackers breached Cuba’s embassy in Washington to spy on communications of dozens of diplomats as the island nation stared down a US naval blockade.
— Byron Wan (@Byron_Wan) April 30, 2026
The campaign began in Jan and compromised the emails of 68 officials, including the Cuban ambassador and the deputy chief of… pic.twitter.com/L9h9gHiub2




 Fire Rescue Victoria said the blaze broke out at Viva Energy's refinery in Geelong about 11pm on Wednesday.
Fire Rescue Victoria said the blaze broke out at Viva Energy's refinery in Geelong about 11pm on Wednesday.
